同步训练-SOK
简介
SparseOperationKit(SOK)是一个 封装了GPU加速操作从而用于稀疏训练/推理的Python包,它与常见的深度学习框架相兼容。
背景
GPU模型并行
对于像CTR类似的稀疏的训练/推荐场景,通常需要大量的参数,大规模参数占据了大量的显存导致无法储存在单个GPU上。但是常见的深度学习框架不支持模型并行(MP),难以充分利用集群中的GPU来加速整个训练/推理过程。
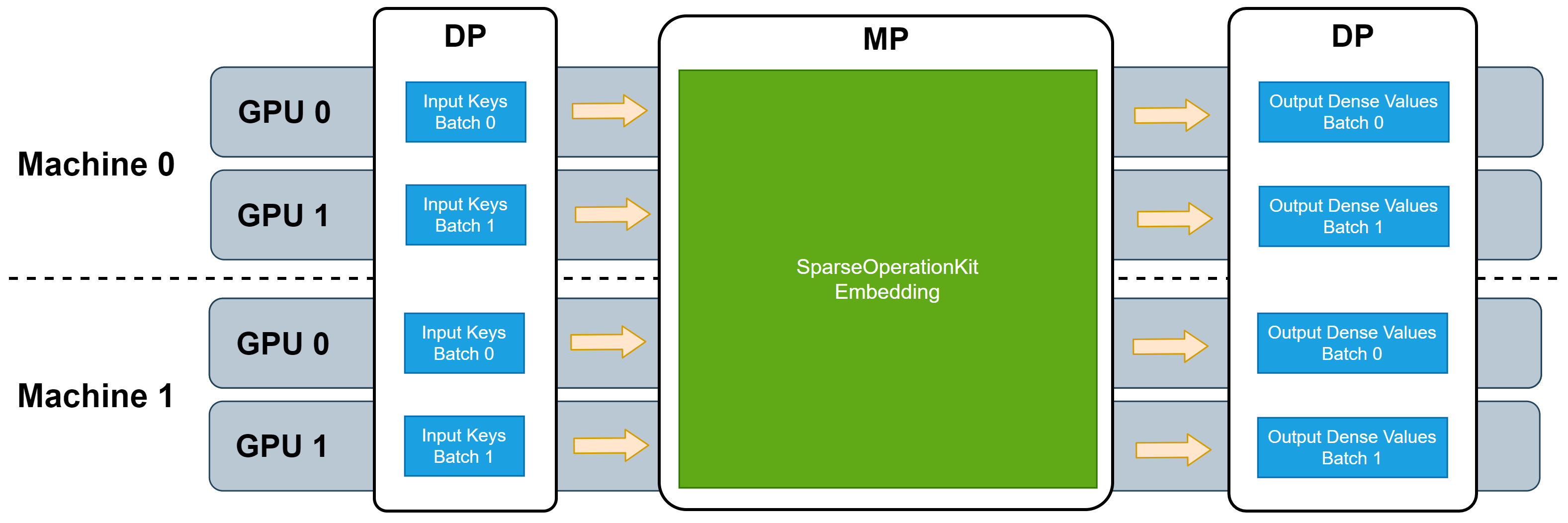
SOK提供了MP的embedding操作可以充分利用所有可用的GPU,包括单机的模型并行和跨节点的模型并行。大多数的深度学习框架都支持数据并行(DP),因此我们将SOK设置成与DP兼容的模式,从而最大限度的减少代码修改。通过SOK的embedding层,可以构建DP和MP混合的DNN模型,其中MP用于embedding参数,从而分布在所有可用的GPU上;DP用于只需要消耗少量GPU显存资源的其他层。
无论对于单机还是多机,通过将一些MP的embedding层整合到SOK中,都可以使这些embedding层充分利用所有可用的GPU显存来储存embedding参数,并且所有使用的GPU都是同步工作。
DP训练通常是借助一些常见的同步训练框架,例如Horovod,Tenorflow Distribute strategy等。由于SOK与DP训练是相互兼容的,因此训练数据可以采用数据并行的模式输入SOK中,这和TF的embedding层的输入模式是相同的,这意味着当使用SOK将DNN模型从单个GPU扩展到多个GPU时,并不需要进行DP和MP之间的转换。
接口介绍
SOK底层支持Horovod作为通讯工具。首先通过SOK的初始化函数进行初始化,然后选择sok两种不同embedding层进行embedding,在反向传播的过程中可以选用SOK优化后的优化器。并且在Utilizers中额外提供了一些功能方便客户使用。
用户在DeepRec可以使用DeepRec的GroupEmbedding功能来使用SOK,或者是SOK原始的接口来使用。
DeepRec的GroupEmbedding接口
Initialize
GroupEmbedding功能提供本地,分布式两种训练模式。我们可以通过分布式模式来使用SOK,首先需要开启设置
tf.config.experimental.enable_distributed_strategy(strategy="collective"),设置后会完成Horovod以及SOK相关模块的初始化。
import tensorflow as tf
##分布式模式需要开启该配置
tf.config.experimental.enable_distributed_strategy(strategy="collective")
Embeddings
GroupEmbedding支持两个层面的API,分别为底层API tf.nn.group_embedding_lookup_sparse 和基于feature_column的API tf.feature_column.group_embedding_column_scope 。
group_embedding_lookup的使用方式如下
def group_embedding_lookup_sparse(params,
sp_ids,
combiners,
partition_strategy="mod",
sp_weights=None,
name=None):
params: List, 该参数可以接收一个或者多个EmbeddingVariable或者是原生Tensorflow Variablesp_ids: List | Tuple , SparseTensor ,values是用于查找的ID 长度必须和params保持一致combiners: List | Tuple 查找完得到的embedding tensor聚合的方式,支持mean和sumpartition_strategy: str 目前暂时不支持sp_weights: List | Typle sp_ids 的 values 的权重。(目前暂时不支持,后续会开放)name: str group的名称
group_embedding_column_scope
def group_embedding_column_scope(name=None):
name: scope的名称
我们只需要先初始化一个上下文 group_embedding_column_scope 并且在这个上下文内完成EmbeddingColumn类的构造,
在后续传入 tf.feature_column.input_layer 时会将这些EmbeddingColumn自动做聚合查询。接口的底层实现是基于tf.SparseTensor设计的。
SOK原始接口
Initialize
sparse_operation_kit.core.initialize.Init(**kwargs)
这个函数用于对SparseOperationKit (SOK)进行初始化。可以缩写为 sok.Init(),DeepRec中,SOK支持Horovod,具体用法如下:
sok_init = sok.Init(global_batch_size=args.global_batch_size)
with tf.Session() as sess:
sess.run(sok_init)
...
Embeddings
Embeddings包含稀疏层和稠密层两个不同的API。稀疏层sok.DistributedEmbedding等价于 tf.nn.embedding_lookup_sparse。稠密层sok.All2AllDenseEmbedding等价于tf.nn.embedding_lookup。
Distributed Sparse Embedding
class sparse_operation_kit.embeddings.distributed_embedding.DistributedEmbedding(combiner, max_vocabulary_size_per_gpu, embedding_vec_size, slot_num, max_nnz, max_feature_num=1, use_hashtable=True, **kwargs)
缩写是 sok.DistributedEmbedding(*args, **kwargs),这是一个用于稀疏embedding层的包装类。 它可以用来创建一个稀疏embedding层,根据gpu_id = key % gpu_num将key分发给每个GPU。
参数如下:
combiner (string):进行 combine 的策略,可以是Mean和Sum。max_vocabulary_size_per_gpu (integer): embedding variable的第一维度,整体维度是[max_vocabulary_size_per_gpu, embedding_vec_size]。embedding_vec_size (integer):embedding variable的第二维度。slot_num (integer): 在每次迭代中同时处理的特征域的数量。max_nnz (integer):每个slot中最大有效key的数量。max_feature_num (integer = slot_num*max_nnz):每个sample中最大有效key的数量。use_hashtable (boolean = True):embedding table中是否使用hash table。
All2All Dense Embedding
classsparse_operation_kit.embeddings.all2all_dense_embedding.All2AllDenseEmbedding(max_vocabulary_size_per_gpu, embedding_vec_size, slot_num, nnz_per_slot, dynamic_input=False, use_hashtable=True, **kwargs)
缩写是sok.All2AllDenseEmbedding(*args, **kwargs)。这是一个封装稠密embedding层的类。 它可以用来创建一个稠密embedding层,根据gpu_id = key % gpu_num将key分发给每个GPU。
参数如下:
combiner (string):进行 combine 的策略,可以是Mean和Sum。max_vocabulary_size_per_gpu (integer): embedding variable的第一维度,整体维度是[max_vocabulary_size_per_gpu, embedding_vec_size]。embedding_vec_size (integer):embedding variable的第二维度。slot_num (integer): 在每次迭代中同时处理的特征域的数量。nnz_per_slot (integer):每个slot中有效key的数量。dynamic_input (boolean = False):input.shape是否是动态的。use_hashtable (boolean = True):embedding table中是否使用hash table。
Optimizers
optimizers优化了tensorflow中的两个optimizer,将其中的unique和unsorted_segment_sum用GPU实现。
Adam optimizer
classsparse_operation_kit.tf.keras.optimizers.adam.Adam(*args, **kwargs)
Local update Adam optimizer
classsparse_operation_kit.tf.keras.optimizers.lazy_adam.LazyAdamOptimizer(*args, **kwargs)
Utilizers
sparse_operation_kit.optimizers.utils.split_embedding_variable_from_others(variables)
该API用于将embedding variable和其他的variable分割开。
参数:
variables (list, tuple):list或者tuple的可训练的tf.Variable。 返回值: -embedding_variables (tuple):输入项中所有的embedding variables。 -other_variables (tuple):输入项中除了embedding variables剩余的所有variables。
详细文档
详细的关于GroupEmbedding功能的接口,可以参考 GroupEmbedding documents
详细各个层的具体文档,用户可以通过 SparseOperationKit documents中看到。