Embedding Lookup异步化
背景
在分布式训练的场景下,随着稀疏模型越来越复杂,模型的输入特征也越来越多。这导致每步训练时worker节点需要在ps节点进行大量的Embedding lookup操作,该操作的在整个端到端的耗时也不断增长,成为模型训练速度的瓶颈,导致不能高效地利用计算资源。
DeepRec提供了Embedding lookup异步化的功能,该功能能够自动地将Embedding lookup部分子图划分出来,并实现与计算主图部分的异步执行,从而实现通信过程与计算过程的重叠,消除模型通信瓶颈对训练的影响,提高计算资源利用率。优化整张图的执行效率,提升训练性能。
由于Embedding lookup操作异步化后,worker端梯度更新部分与Embedding lookup部分位于两张图内,将导致worker端无法获得PS端最新的Embedding lookup结果,有可能影响训练收敛速度和模型效果。
功能说明
在用户的原图有io stage阶段的前提下,通过开启async embedding功能,实现Embedding子图的自动切分,并实现embedding lookup的异步化,从而提高训练性能。
注意:
该功能开启的前提条件是用户的原图中存在一个io stage阶段,该阶段应当在读取样本之后,embedding lookup之前。相关内容请参见流水线-Stage一节。
该功能与自动流水线-SmartStage冲突,开启async embedding功能后将自动关闭SmartStage功能。
用户接口
目前,该功能实现了DeepRec中以下Embedding lookup函数接口的支持。
tf.contrib.feature_column.sequence_input_layer()
tf.contrib.layers.safe_embedding_lookup_sparse()
tf.contirb.layers.input_from_feature_columns()
tf.contirb.layers.sequence_input_from_feature_columns()
tf.feature_column.input_layer()
tf.nn.embedding_lookup()
tf.nn.embedding_lookup_sparse()
tf.nn.safe_embedding_lookup_sparse()
tf.nn.fused_embedding_lookup_sparse()
tf.python.ops.embedding_ops.fused_safe_embedding_lookup_sparse()
该功能在ConfigProto中定义了如下配置选项
sess_config = tf.ConfigProto()
sess_config.graph_options.optimizer_options.do_async_embedding = True
sess_config.graph_options.optimizer_options.async_embedding_options.threads_num = 4
sess_config.graph_options.optimizer_options.async_embedding_options.capacity = 4
sess_config.graph_options.optimizer_options.async_embedding_options.use_stage_subgraph_thread_pool = False # 可选
sess_config.graph_options.optimizer_options.async_embedding_options.stage_subgraph_thread_pool_id = 0 # 可选
其中:
配置选项 |
含义 |
默认值 |
|---|---|---|
do_async_embedding |
Async Embedding开关 |
False(关闭) |
async_embedding_options.threads_num |
异步化执行embedding lookup子图线程数 |
0 (需手动指定) |
async_embedding_options.capacity |
缓存异步化执行embedding lookup子图结果的最大个数 |
0 (需手动指定) |
async_embedding_options.use_stage_subgraph_thread_pool |
是否使用独立线程池运行embedding lookup子图,需要先创建独立线程池。 |
False(可选,若为True则必须先创建独立线程池) |
async_embedding_options.stage_subgraph_thread_pool_id |
如果启用独立线程池运行embedding lookup子图,该选项用于指定独立线程池索引,需要先创建独立线程池,并打开async_embedding_options.use_stage_subgraph_thread_pool选项。 |
0,(可选,索引范围为[0, 创建的独立线程池数量-1]) |
注意事项
async_embedding_threads_num并不是越大越好,只需要可以让计算主图部分不必等待embedding lookup子图的结果即可,数量更大会抢占模型训练的计算资源,同时也会占用更多的通信带宽。建议按下述公式设置,可以从1开始向上调整。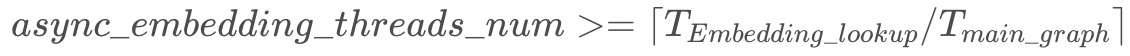
async_embedding_capacity更大会消耗更多的内存或缓存。同时也会造成缓存的embedding lookup子图结果与从PS端获取的最新结果有较大差异,造成训练收敛慢。建议设置为async_embedding_threads_num的大小,可以从1开始向上调整。独立线程池功能可以使不同的Stage子图运行在不同的线程池中,避免与计算主图和其他子图竞争默认线程池。关于如何创建独立线程池,可以参见流水线Stage 一节。
CPU集群性能对比
机型为Aliyun ECS实例 ecs.hfc7.24xlarge,10台组成训练集群。
集群配置如下表所示。
项目 |
说明 |
|---|---|
CPU |
Intel Xeon Platinum (Cooper Lake) 8369 96核心 |
MEM |
192 GiB |
网络带宽 |
32 Gbps |
训练配置
项目 |
说明 |
|---|---|
PS 数量 |
8 |
worker数量 |
30 |
PS 核心数 |
15 |
worker 核心数 |
10 |
模型性能
模型 |
baseline性能(global steps/sec) |
async embedding功能性能(global steps/sec) |
加速比 |
|---|---|---|---|
DLRM |
1008.6968 |
1197.932 |
1.1876 |