BFloat16
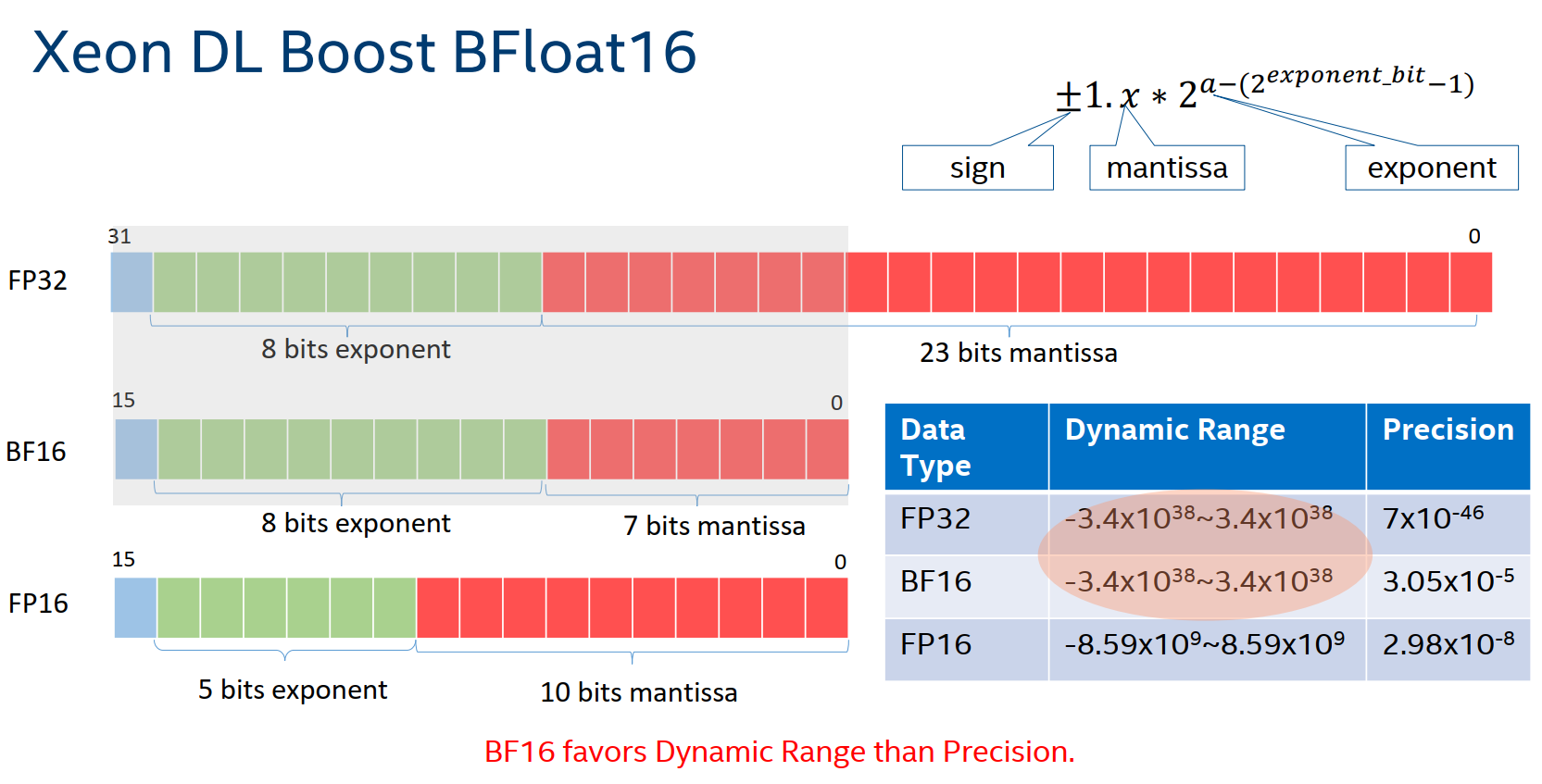
BFloat16 (BF16) is a computational format and the instruction for accelerating deep learning training and inference, which is supported on the third-generation Intel® Xeon® Scalable processor Cooper Lake AliCloud hfg7 specification family and its successor processors. Below shows the comparison with other commonly used data formats:
Requirments and methods
Requirements:The cloud instance requires to be the third-generation Intel® Xeon® Scalable processor Cooper Lake AliCloud hfg7 specification family. It also requires to use DeepRec which is compiled and optimized by oneDNN in order to provide BF16 instruction acceleration, details of which can be found in the oneDNN section.
Method:As the recommended scenarios are extremely demanding in terms of model accuracy, in order to improve model performance while taking into account model accuracy, users could control the BF16 computing graph freely in the following way:
Step 1: Add
.keep_weights(dtype=tf.float32)aftertf.variable_scope(…)to keep the current weights as FP32.Step 2: Add
tf.cast(…, dtype=tf.bfloat16)to transfer the input tensors to BF16 type.Step3: Add
tf.cast(…, dtype=tf.float32)to transfer the output tensors to FP32 type.
with tf.variable_scope(…).keep_weights(dtype=tf.float32):
inputs_bf16 = tf.cast(inputs, dtype=tf.bfloat16)
… // BF16 graph, FP32 weights
outputs = tf.cast(outputs_bf16, dtype=tf.float32)
Example:
import tensorflow as tf
inputs = tf.ones([4, 8], tf.float32)
with tf.variable_scope('dnn', reuse=tf.AUTO_REUSE).keep_weights(dtype=tf.float32):
# cast inputs to BF16
inputs = tf.cast(inputs, dtype=tf.bfloat16)
outputs = tf.layers.dense(inputs, units=8, activation=tf.nn.relu)
outputs = tf.layers.dense(inputs, units=1, activation=None)
# cast ouputs to FP32
outputs = tf.cast(outputs, dtype=tf.float32)
outputs = tf.nn.softmax(outputs)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(outputs))
Special Reminder: according to the experience of parameters tuning, usually the last layer of DNN network in a multi-layer DNN network has the most impact on the accuracy of the model, which occupies a lower computational ratio. So the last layer of DNN network can be converted to FP32 type to run, which can improve the computational performance of the model training while preserving the accuracy of the model.
To maintain consistency with the accuracy of the model without BF16 optimization, DeepRec provides the keep_weights(dtype=dtypes.float32) method in variable_scope. With this method, all variables in this variable field will be saved in FP32 format, which significantly reduce the cumulative summation error of variables. And the cast operation is automatically added to the graph, converting it to BF16 format for computation. To reduce the extra computational overhead of the cast operation introduced, DeepRec automatically fuses the cast operator with its nearest operator to improve the operation performance. DeepRec will perform the following fusion operations on cast-related operators.
MatMul + Cast
Concat + Cast
Split + Cast
Performance comparison
Use models in DeepRec Modelzoo to compare the DeepRec with BF16 and FP32 to see the performance improvement. Models in Modelzoo can enable the BF16 feature by adding --bf16 parameter.
Use Aliyun ECS cloud server as benchmark machine, Intel 3rd Xeon Scalable Processor(Cooper Lake) specification ecs.hfg7.2xlarge
Hardware configuration:
Intel(R) Xeon(R) Platinum 8369HC CPU @ 3.30GHz
CPU(s): 8
Socket(s): 1
Core(s) per socket: 4
Thread(s) per core: 2
Memory: 32G
Software configuration:
kernel: 4.18.0-348.2.1.el8_5.x86_64
OS: CentOS Linux release 8.5.2111
GCC: 8.5.0
Docker: 20.10.12
Python: 3.6.8
Performance Result:
Throughput |
WDL |
DeepFM |
DSSM |
|---|---|---|---|
FP32 |
15792.49 |
30718.6 |
114436.87 |
FP32+BF16 |
22633.8 |
34554.67 |
125995.83 |
Speedup |
1.43x |
1.12x |
1.10x |
BF16 has little effect on the AUC metric of model training, more details of the difference can be found in the documentation of each model in the model zoo.